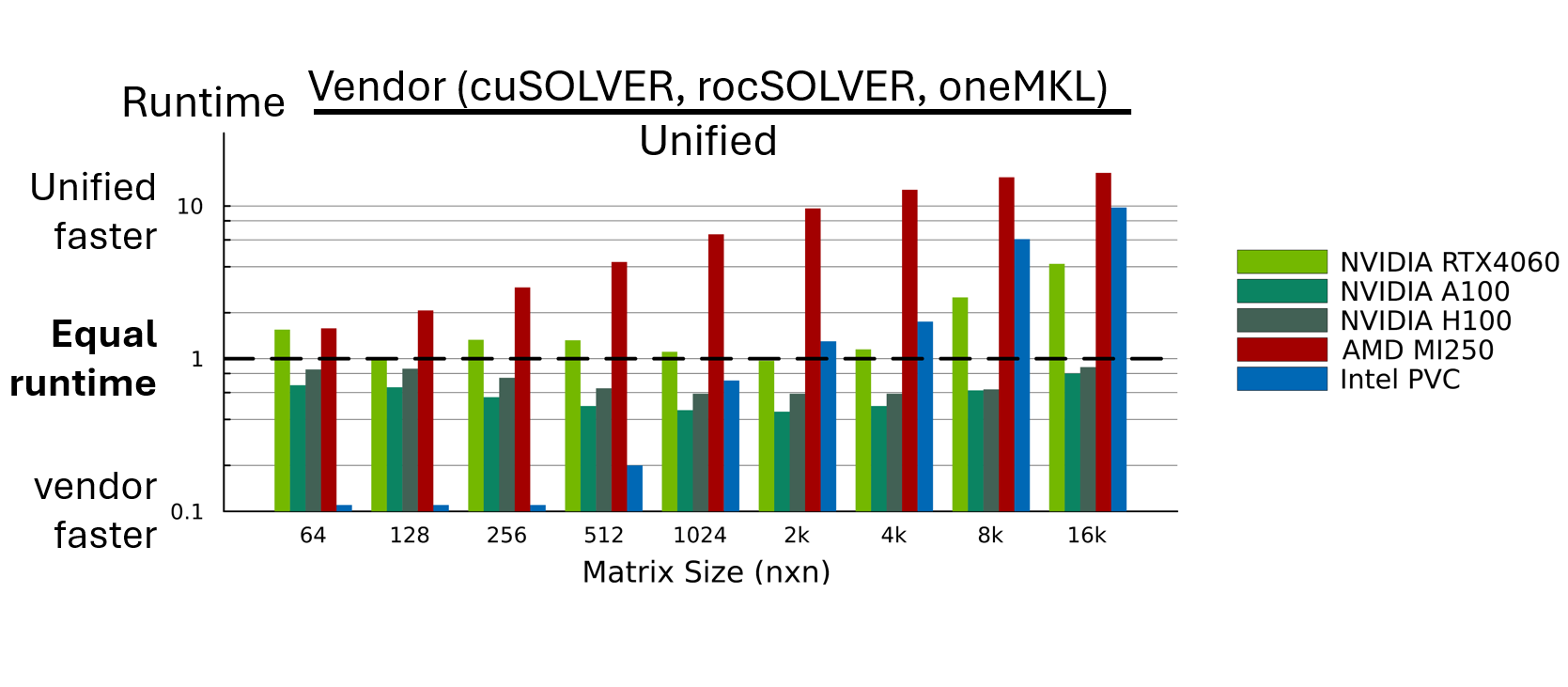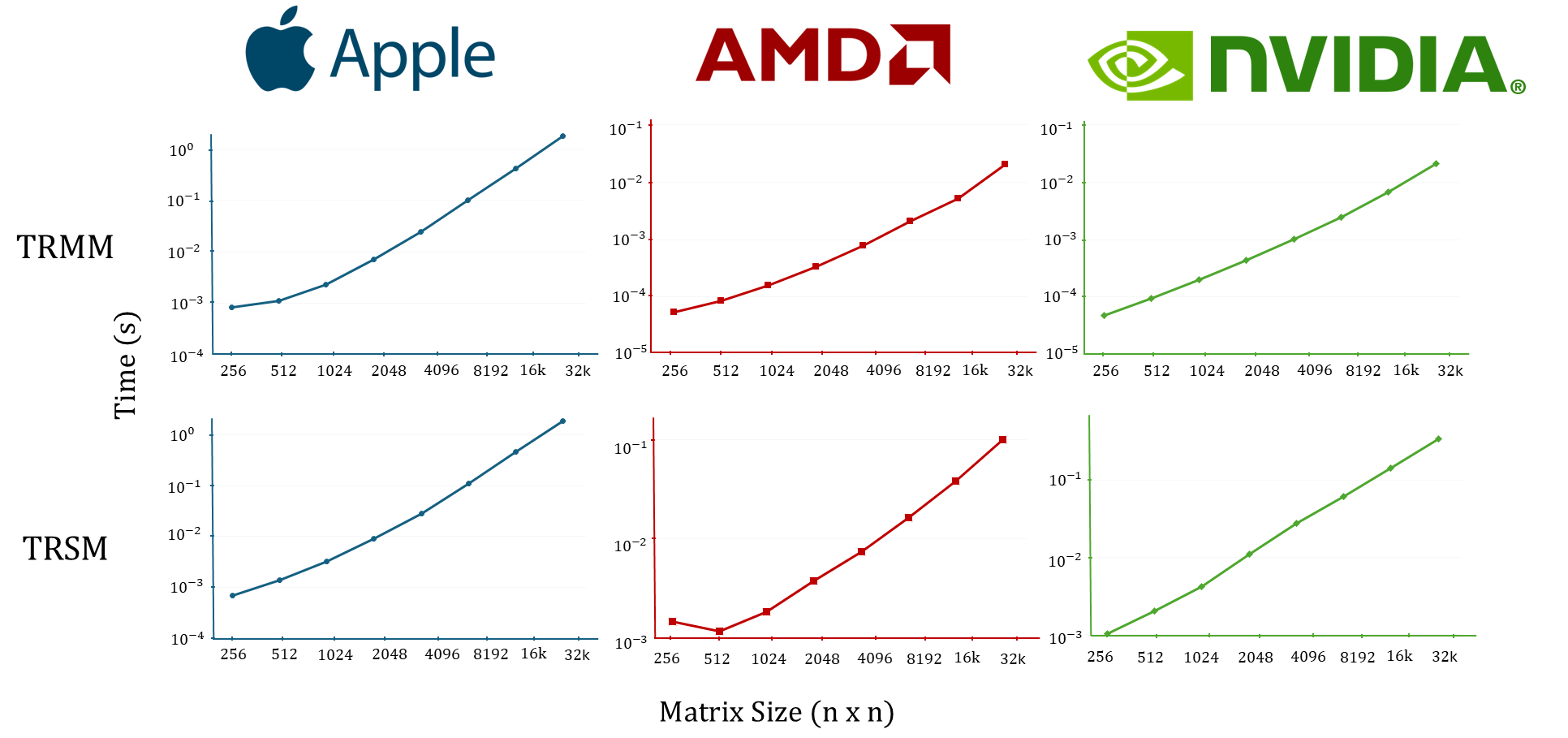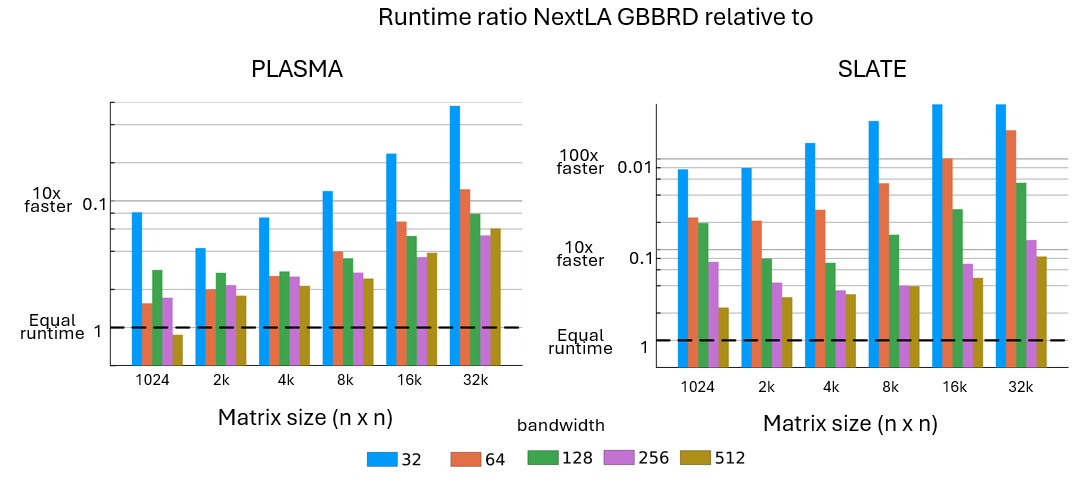
Bidiagonalization of banded matrices
In the past, bidiagonalization through bulge-chasing was believed to be a CPU-only algorithm since it is memory bound. Not anymore. Low-level GPU memory has increased and we present the first GPU algorithm for reducing a banded matrix to bidiagonal form, ouperforming HPC libraries PLASMA and SLATE by orders of magnitude.
Read more